
Hierarchical clustering
Rafael Irizarry
With the distance between each pair of movies computed, we need an algorithm to define groups from these. Hierarchical clustering starts by defining each observation as a separate group, then the two closest groups are joined into a group iteratively until there is just one group including all the observations.
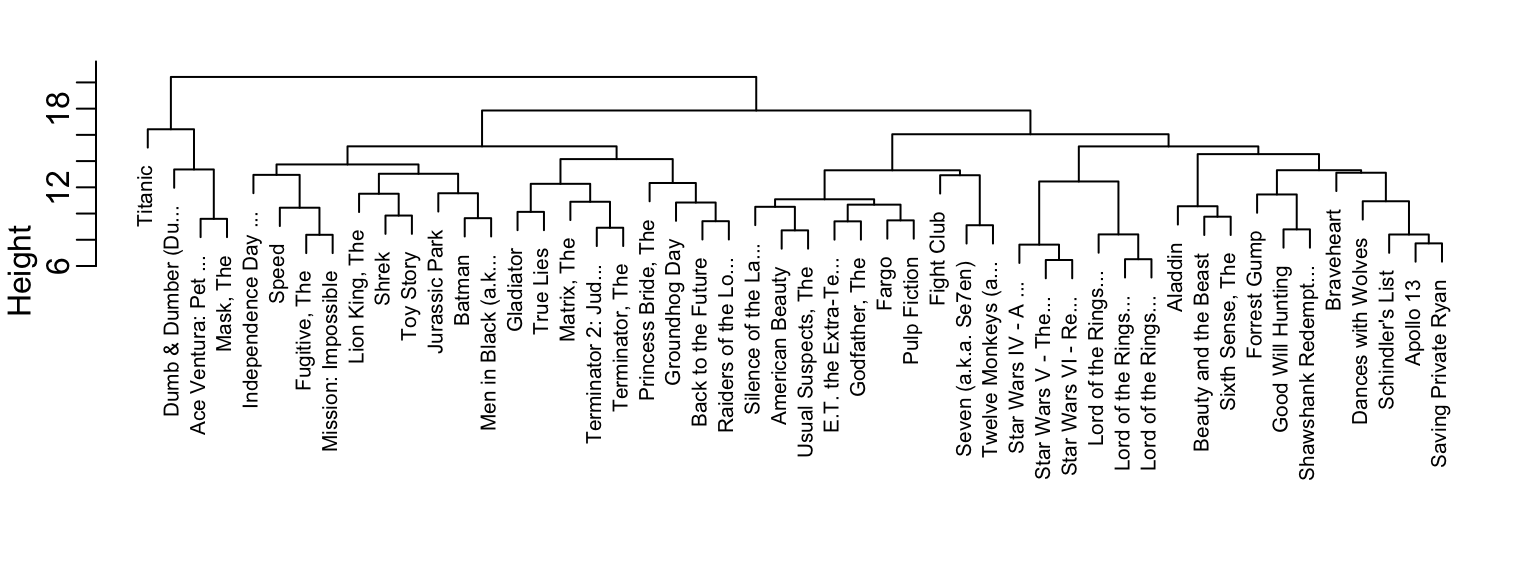
This graph gives us an approximation the distance between any two movies. To find this distance we find the first location, from top to bottom, where these movies split into two different groups. The height of this location is the distance between these two groups. So, for example, the distance between the three Star Wars movies is 8 or less, while the distance between Raiders of the Lost Ark and Silence of the Lambs is about 17.
To generate actual groups we can do one of two things: 1) decide on a minimum distance needed for observations to be in the same group or 2) decide on the number of groups you want and then find the minimum distance that achieves this.
Note that the clustering provides some insights into types of movies. Group 4 appears to be blockbusters, and group 9 appears to be nerd movies. We can also explore the data to see if there are clusters of movie raters.
